| web interface | WebAUGUSTUS | accuracy results | download AUGUSTUS | data sets | predictions | references |

Features/News:
- The source code is now hosted at GitHub: Augustus at GitHub. Please create an issue there for source code related problems (compilation, crash).
- The download version of AUGUSTUS can incorporate data from RNA-Seq (short cDNA reads, single or paired-end, e.g. from Illumina or SOLiD) as documented on this wiki page on RNA-Seq integration (May 15, 2012).
- Please look into this forum for questions and answers (Q&A) to see if your questions have already been asked.
- We now offer another web service that allows to upload whole genome data for training AUGUSTUS and annotating a genome.
- AUGUSTUS now has a protein profile extension (PPX) which allows to use protein family specific conservation in order to identify members and their exon-intron structure of a protein family given by a block profile. The block profile can be constructed with accompanying scripts from a multiple protein sequence alignment. For more details please refer to the RUNNING-AUGUSTUS.md.
- We now have a fully automatic annotation pipeline for download with the distribution. For a new genome you can feed the pipeline only with your sequences, a genome and EST or 454 reads, and then you get your genome-wide predictions out. Training is done automatically. (June 26th, 2009)
- The results can be displayed automatically in the genome browser Gbrowse. You can browse the gene predictions together with the input sequence, the constraints and the cDNA alignments. Gbrowse also enables you to simultaneously display your own annotation and to export the image in scalable vector graphics format.
- You can upload cDNA sequences together with the genomic DNA. Your ESTs or mRNA will be used to improve the gene prediction.

- AUGUSTUS ususally belongs to the most accurate programs for the species it is trained for. Often it is the most accurate ab initio program. For example, at the independent gene finder assessment (EGASP) on the human ENCODE regions AUGUSTUS was the most accurate gene finder among the tested ab initio programs. At the more recent nGASP (worm), it was among the best in the ab initio and transcript-based categories. See accuracy statistics for further statics.
- AUGUSTUS is retrainable. It comes with a training program that estimates the parameters given a training set of known genes. It also comes with an optimization script that tries to find values for the meta parameters, like splice window sizes, that optimize the prediction accuracy.
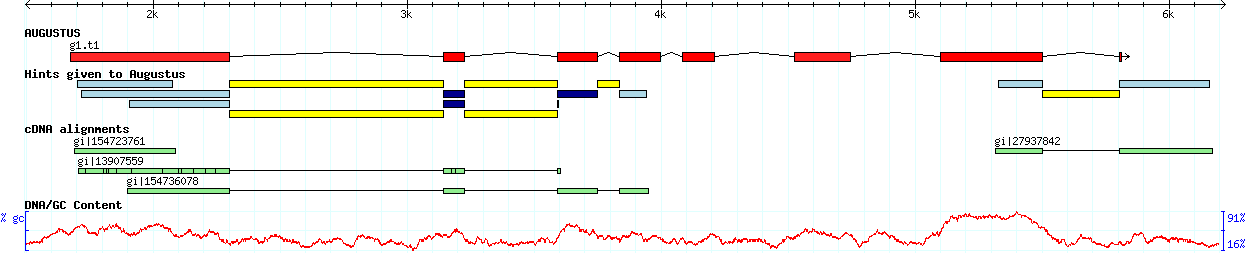
- AUGUSTUS can be used ab initio and has a flexible mechanism for incorporating extrinsic
information, e.g. from EST alignments and protein alignments. Here is an example from the UCSC
Genome Browser where the AUGUSTUS prediction incorporates mRNA alignments, EST alignments,
conservation and other sources of information:

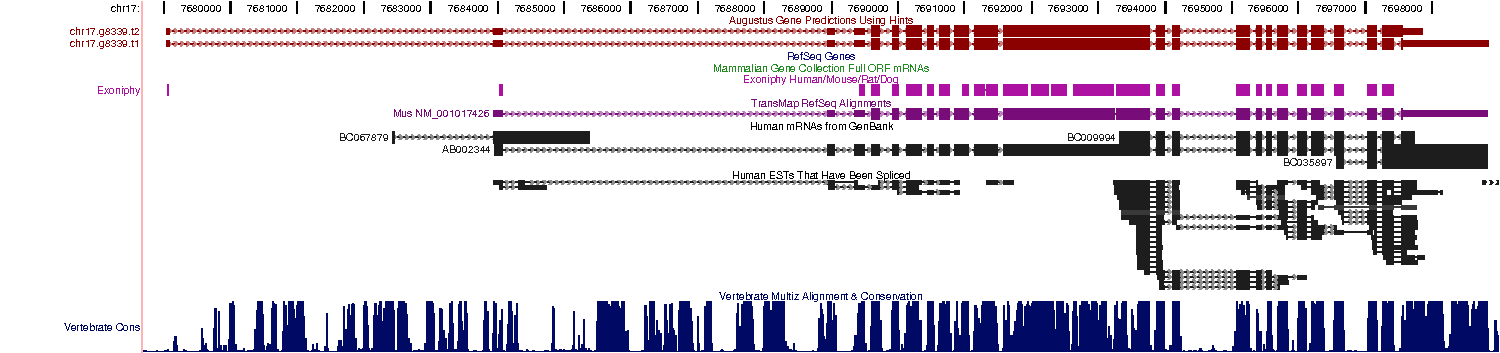
- AUGUSTUS can predict alternative splicing and alternative transcripts. It can do this for example
when the EST alignments suggest alternative splicing like in this example:

- AUGUSTUS can predict the 5'UTR and 3'UTR including introns. This is in particular helpful when using EST alignments as the majority of ESTs aligns in the untranslated regions (example). This feature is currently only trained for human, the red algae Galdieria sulphuraria, Caenorhabditis elegans, Toxoplasma gondii, Chlamydomonas reinhardtii, pea aphid, Culex pipens (3'UTR only), butterfly, Bombus terrestris/impatiens, chlorella, elephant shark, honeybee, Leishmania tarentolae, maize, rhodius, tomato, trichinella.
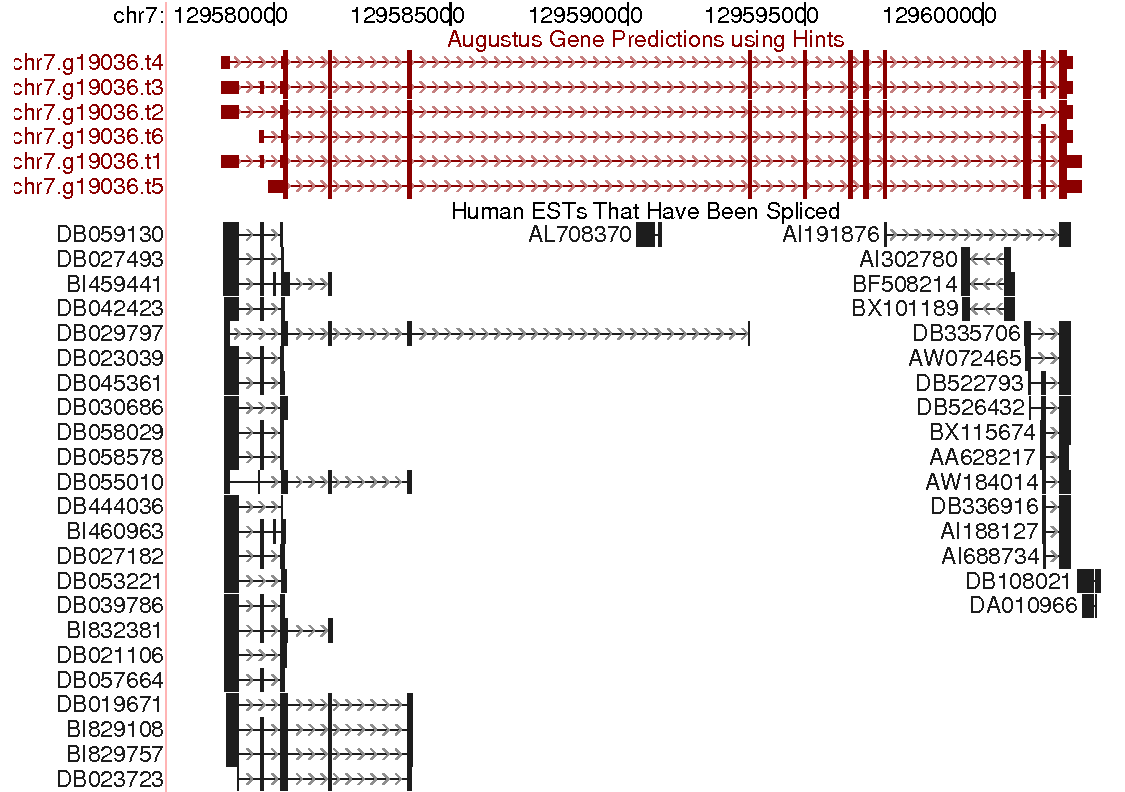
- AUGUSTUS can report a large number of alternative genes, including probabilities for the transcripts and each exon and intron. You can make AUGUSTUS predict suboptimal gene structures (example) and you can adjust command line paramters to regulate the number of reported alternatives.
{kind=link}
Species:
AUGUSTUS has currently been trained on species specific training sets to predict genes in the following species. Note that for closely related species usually only one version is necessary. For example, the human version is good for all mammals. Contributions.| animals: | alveolata: | plants and algae: | fungi: | bacteria: | archaea: |
|---|---|---|---|---|---|
|
Acyrthosiphon pisum Aedes aegypti Amphimedon queenslandica Ancylostoma ceylanicum Apis mellifera Bombus terrestris Brugia malayi Caenorhabditis elegans Callorhinchus milii Culex pipiens Danio rerio Drosophila melagonaster Gallus gallus Heliconius melpomene Homo sapiens Nasonia vitripennis Petromyzon marinus Rhodnius prolixus Schistosoma mansoni Tribolium castaneum Trichinella spiralis Xipophorus maculatus |
Tetrahymena thermophila Toxoplasma gondii |
Arabidopsis thaliana Chlamydomonas reinhardtii Galdieria sulphuraria Nicotiana attenuata Oryza brachyantha Solanum lycopersicum Theobroma cacao Triticum aestivum Zea mays |
Aspergillus fumigatus Aspergillus nidulans Aspergillus oryzae Aspergillus terreus Botrytis cinerea Candida albicans Candida guilliermondii Candida tropicalis Chaetomium globosum Coccidioides immitis Conidiobolus coronatus Coprinus cinereus Cryptococcus neoformans Debaryomyces hansenii Encephalitozoon cuniculi Eremothecium gossypii Fusarium graminearum Histoplasma capsulatum Kluyveromyces lactis Laccaria bicolor Lodderomyces elongisporus Magnaporthe grisea Neurospora crassa Phanerochaete chrysosporium Pichia stipitis Rhizopus oryzae Pneumocystis jirovecii Saccharomyces cerevisiae Schizosaccharomyces pombe Ustilago maydis Verticillium longisporum Yarrowia lipolytica |
Escherichia coli Staphylococcus aureus Thermoanaerobacter tengcongensis |
Sulfolobus solfataricus |